
Big Data Aplicado
Profesor: Jon Ander Maiz
En esta asignatura se trabajan distintas herramientas que permiten procesar, almacenar y visualizar gran cantidad de datos en tiempo real.
En el mundo, el 90% de los datos que tenemos se crearon en los últimos dos años. Esta regla se repite cada año que vuelven a salir estadísticas. Desde 2010, se ha multiplicado por 74 la cantidad de datos que existen.
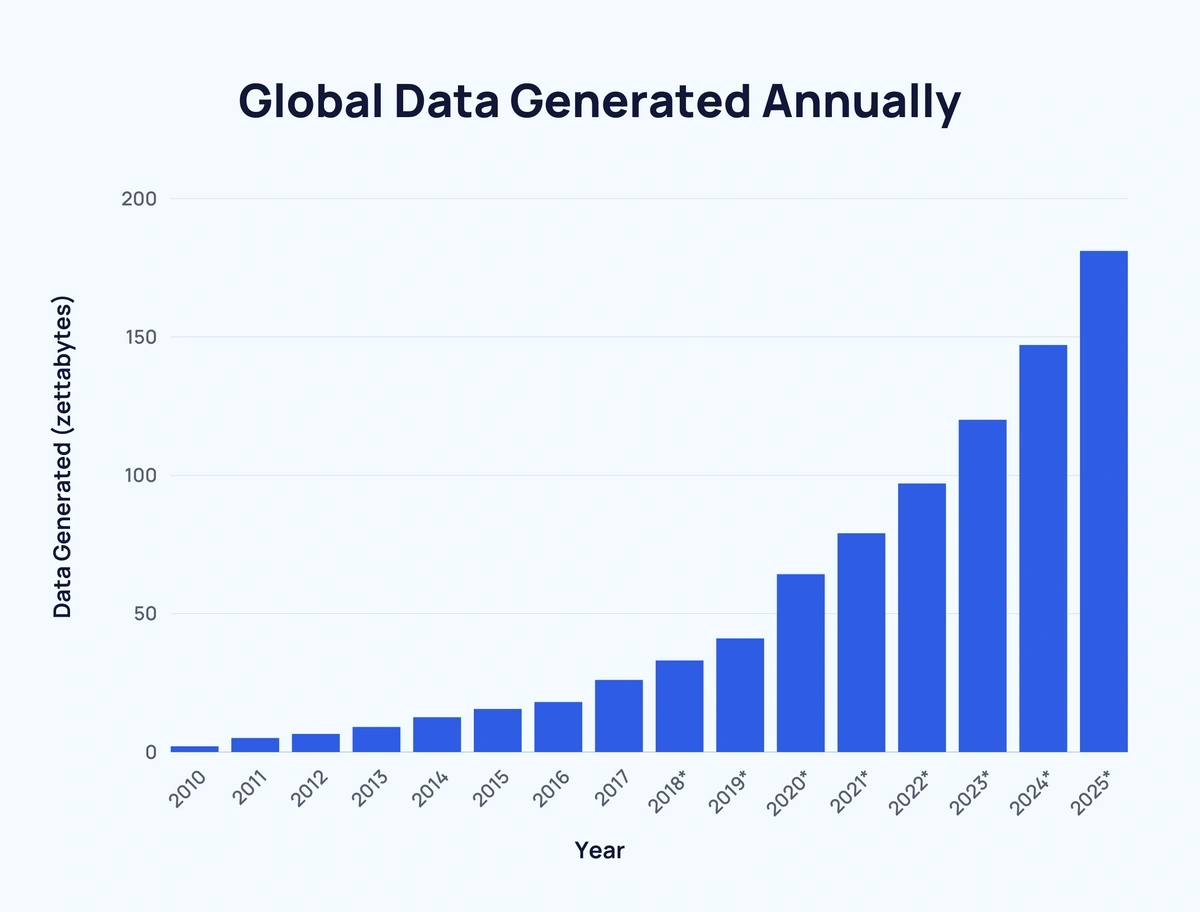
Esto nos habla de la importancia de saber manejar cada vez más datos de manera simultánea.
Primeras semanas
Empezamos el curso instalando una MV Ubuntu 24.04, ya que una gran parte del software que utilizaremos lo instalaremos ahí (más adelante veremos otras maneras de trabajar).


Hecho eso, trabajaremos con python y pandas para empezar a procesar distintos archivos con datos reales que obtendremos de distintas fuentes.
Una vez visto el procesamiento básico, aprenderemos a usar InfluxDB, para almacenar datos de series temporales e ingestar estos datos que hemos procesado.
InfluxDB: Es una base de datos de series temporales (time-series database) de código abierto. Está optimizada para el almacenamiento y la consulta rápida de grandes volúmenes de datos con marca de tiempo, como métricas de monitorización, datos de sensores (IoT) o eventos de aplicaciones.

Una vez tengamos almacenados los datos, aprenderemos a visualizarlos utilizando grafana. Veremos creación de dashboard con distintos tipos de gráficas, creación de alarmas y avisos, enriquecimiento de los datos…

Grafana: Es una plataforma de visualización y análisis de datos de código abierto. Permite crear dashboards interactivos y personalizables para monitorizar y entender métricas, logs y otros datos provenientes de diversas fuentes (como InfluxDB).
Visto esto, veremos otras maneras de procesar datos, como node-red, con la que veremos también cómo ingestar datos desde APIs.
Con todo esto, los alumnos pasan a trabajar en el Reto 0, que juntará lo visto en las distintas asignaturas en un reto que perfectamente podría encontrarse en el entorno laboral.
Todas las descripciones más detalladas de los retos están en el apartado Proyectos y Retos.
Noviembre-Diciembre
Hecho el reto 0, continuamos con otras herramientas de procesamiento y almacenamiento de distintos tipos de datos.
Comenzaremos a entrar en el mundo de ELK (Elasticsearch, Logstash, Kibana).
Elasticsearch: Es un motor de búsqueda y análisis distribuido, de código abierto. Permite indexar, buscar y analizar grandes volúmenes de datos (estructurados o no estructurados) de forma rápida y casi en tiempo real, siendo popular para analítica de logs y búsqueda de texto completo.
Logstash: Es una herramienta de código abierto para la ingesta y procesamiento de datos del lado del servidor. Permite recolectar datos de múltiples fuentes, transformarlos o enriquecerlos, y luego enviarlos a un destino (“stash”), comúnmente Elasticsearch.
Kibana: Es una plataforma de visualización y exploración de datos de código abierto, diseñada específicamente para trabajar con Elasticsearch. Permite a los usuarios crear dashboards interactivos, gráficos, mapas y realizar búsquedas para analizar y comprender los datos almacenados en Elasticsearch.



Veremos cómo procesar datos utilizando logstash, utilizando las distintas opciones que nos da. Una vez procesados, los subiremos a Elasticsearch, donde veremos múltiples elementos que nos permitirán optimizar nuestros datos, para sacar el máximo partido de los mismo. Finalmente graficaremos esos datos en Kibana para facilitar la toma de decisiones.
A su vez, se proporcionará material de más herramientas del Elasitc Stack, que nos permitirá monitorizar el funcionamiento de nuestras máquinas de manera sencilla, para tener un control total sobre nuestro cluster.
Todo esto nos llevará al reto 1, donde ELS se usará como base de datos + buscador de un chatbot.
Enero-Febrero
En la parte final del curso, trabajaremos casi en su totalidad en la nube, utilizando para ello laboratorios de AWS, donde podremos desplegar multitud de herramientas sin coste alguno, gracias a ser parte de AWS Academy.

Empezaremos usando de nuevo node-red+influxdb+grafana, pero esta vez en tres máquinas virtuales creadas en AWS (EC2), y haciendo que se comuniquen entre las 3 mediante grupos de seguridad, habilitando puertos…
Después, aprenderemos a usar DynamoDB, la base de datos basada en keys de AWS. A su vez iremos aprendiendo sobre otras herramientas como Lambda, IAM, S3, Cloudwatch…
Finalmente haréis el último reto, donde el último año se diseñó una herramienta similar a X-Ray de Prime, para reconocimiento de caras y objetos.